Performance at Scale
Ratify’s security guarantees rely on its performance at various cluster scales. This document specifies the current ratify performance capabilities. It presents the most recent performance data findings and explains how the data was collected via an automated pipeline.
Note: These benchmarks are based on Azure end-to-end testing data. The performance framework applied is extensible and cloud-provider agnostic.
Last test conducted: September 2023
Supported Limits:
- Single Ratify Pod: supports verification requests for up to 1k pod clusters, where each pod results in 50 supply chain artifacts being verified.
- HA enabled Ratify Pod with 3 replicas: supports verification requests for up to 10k pod clusters
- NOTE: For Azure users with large kubernetes clusters greater than 200 pods, a medium or large ACR region MUST be used to avoid large ACR throttling.
Major Findings:
- Ratify is primarily constrained by the memory consumption limits (512Mib) and the registry throttling limits (varies by registry service tier and region for ACR)
- Single instance Ratify can support up to 1k pods comfortably. Workloads larger than that trigger high memory usage. This eventually leads to the pod being Out-of-Memory (OOM) killed.
- Deployment and Job workloads result in similar Ratify performance. Concurrent jobs with many replicas seem to yield slightly larger concurrent requests to Ratify. However, the Ratify request durations and resource consumption is similar.
- Minimal registry request throttling (429 reponse) can lead to drastic performance degradation for Ratify. In large clusters (10k pods+) in XS ACR regions, Ratify's 429 rate spikes. This leads to back-off retries that prolong each verification operation. Longer running requests can lead to more concurrent requests being processed at once, which eventually increases pod memory usage. Throttling also increases the number of request timeouts leading to the K8s workload resource attempting to recreate the pod. This in turn generates more requests to Ratify.
- Ratify's memory usage is directly correlated to the number of resources on the cluster. Memory usage is a good indicator for Ratify deployment scale out. We may consider adding a Horizontal Pod Autoscaler (HPA) based on memory consumption.
- Ratify's CPU usage is fairly minimal. Although CPU usage was not measured over the course of the test, but instead measured once after, the CPU limits seem to be well below the currently limits set. We may consider lowering the CPU request.
- The performance benefit of the distributed cache for high availability usage is inconclusive. Large cluster tests with distributed cache enabled in an XS region resulted in anomalous behavior and the logs show very slow request processing. Investigation as to why there is a bottleneck compared to when distributed cache is disabled is tracked here
Testing Details
Performance testing framework was designed to measure the performance of the Ratify service in a Kubernetes cluster as an external data provider to Gatekeeper. Ratify was deployed in clusters of various size, installed with different performance configurations, and measured against various workload sizes. To start, an Azure-specific performance pipeline that implements this framework was created to enable large scale automated testing of the scenarios discussed below.
Azure pipeline implementation details can be found here
Note: This framework can be applied for different cloud providers
What does the pipeline do?
- Create a cluster with specified node count
- Configure identity and RBAC so cluster and Ratify can pull from configured registry. Also apply the roles so Ratify can download certificates from Key Management Service.
- Install Gatekeeper and accompanying
ConstraintandConstraintTemplate. - Install Ratify with test-specific configuration
- Install Prometheus
- Generate a set of workload resource templates depending on the test configuration. Specifically, generate templates based on number of containers and image references with attached artifacts.
- Begin
ResourceUsagemeasurements to understand resource consumption as resources are created in cluster. - Apply test workloads and wait for deployment to succeed. After, destroy the resources.
- Scrape Ratify metrics using prometheus
- Upload logs for Gatekeeper and Ratify. Upload resource consumption report.
Variables
Cluster Size
The node count of the cluster needs to scale according to the workload size. The test conducted imposed a 40 pod scheduler limit per node.
Workload pod counts: 200, 2000, 10000 Cluster node counts: 11, 62, 307 Node Type: Standard_D4s_v3 4vCPUs 16Gib memory. Details here
Registry Region Size
ACR has different region sizes. The size of the region determines the max RPS for a single ACR from a single IP. The test focuses on 4 regions of varying sizes.
- East US 2: Large
- East US 2 Availability-Zone-enabled: Medium
- Central US Availability-Zone-enabled: Small
- East US 2 Canary: Extra Small
ACR regions were selected by size and proximity to the cluster region of East US 2 to minimize cross-region latency.
Workload Resource Type
The test focused on Deployment and Job workloads. Most tests were conducted with a single Deployment with varying replica counts. Job tests applied 5 Jobs simultaneously splitting total pod count evenly across each job.
Distributed caching
Majority of tests enabled distributed caching across 3 replicas for optimal performance configuration. A subset tested Ratify with 3 replicas with the distributed cache disabled. Distributed caching is critical for reducing duplicate registry requests. It is also essential for external plugins utilizing caching.
Test enabled/disabled RATIFY_EXPERIMENTAL_HIGH_AVAILABILITY feature flag
Ratify Single Instance
This test aimed to determine the workload threshold for a single instance of Ratify before over-exhaustion. Single instance vs 3 Ratify Replicas.
Measurements
- Registry Throttling
- # of 429 http responses returned from registry
- This indicates supported registry RPS in a particular region.
- Ratify pod(s) CPU/memory usage: High Memory consumption is correlated with high RPS load on Ratify.
- Approximate max verification request duration: Helpful to understand initial non-cached request durations
- P95 verification request duration: Shows distribution of request durations through duration of the test.
- Approximate max mutation request duration: Helpful to understand initial non-cache request durations.
- P95 verification request duration: Shows distribution of request duration throughout the duration of test.
- # Ratify Container Restarts: early indication of resource exhaustion and blocking errors at scale
- # Ratify Pod OOMKilled: definite signal of resource over-exhaustion
Data Matrix
Each scenario is grouped by color. Red boxes indicate threshold violations.
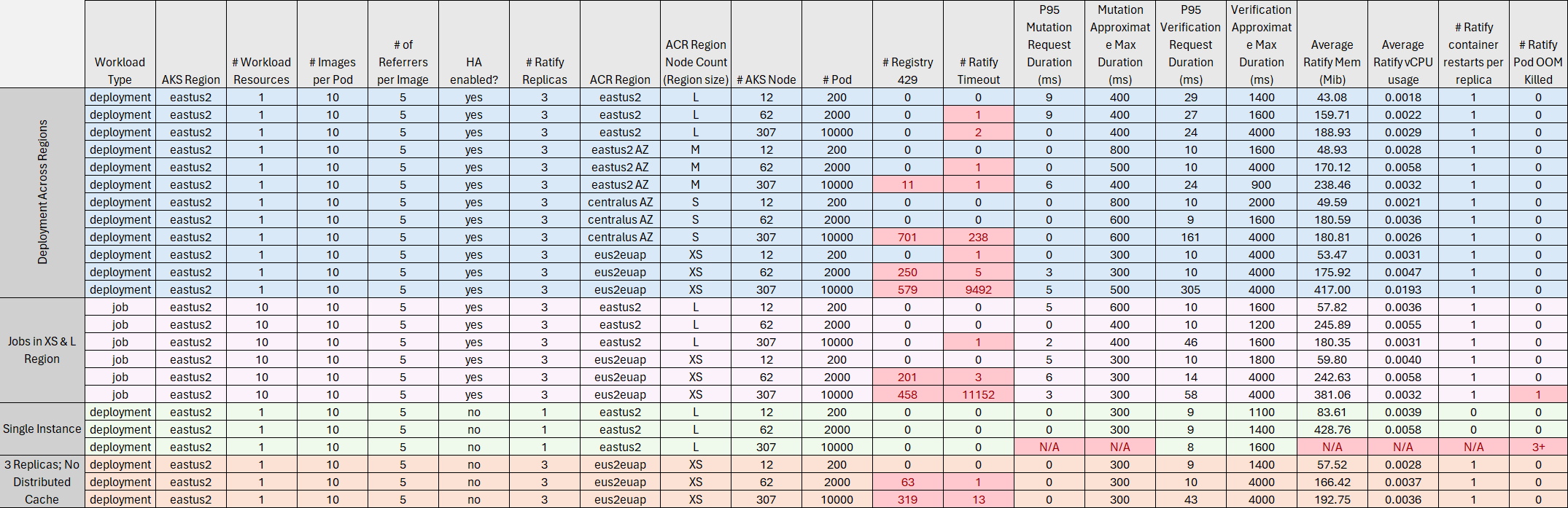
Test Scenarios Explained
Deployments across ACR Regions (Blue)
The results confirmed the hypothesis that as the ACR region size decreases, the registry throttling increases leading to more Ratify timeouts. As pod count increases, the effects of throttling worsen especially in the XS region for ACR. (Note: the extremely large timeout count for 10k pods in XS region is linked to an issue with the HA setup. More investigation required)
P95 durations for both mutation and verification are very low. Majority of requests benefit from the cache.
CPU grows as workload size increases; however it remains very low compared to the limit. Memory usage significantly increases with workload size. Ratify is most susceptible to OOM issues.
Jobs vs Deployment workloads (Purple)
Jobs were sharded over 5 deployments applied simultaneously. The test pod count was evenly distributed across each Job. Overall, request durations between Jobs and Deployment were fairly similar. Jobs in general led to a higher memory usage for Ratify, hinting to a higher RPS load on Ratify. This is in line with the original hypothesis that multiple smaller workload resources could potentially trigger a higher number of concurrent requests due to the Kubernetes scheduler processing each workload resource in parallel.
Single Instance vs Replicas (Green)
The purpose of this test is to measure the limit for a single Ratify pod to service all cluster verification/mutaton requests. Ratify single instance pod performed well up to 2k pods. At that point, memory usage grew to the out of bounds.
Distributed caching (Orange)
The goal for this test is to measure if distributed caching results in less registry throttling. From the data, we can see that at smaller scales and for larger regions, both distributed caching and single instance caching performed well. For the XS region of ACR in the largest workloads, the request processing slowed down and the cache miss rate spiked leading to request timeouts. This result is not expected and is a symptom of an underlying issue. Investigation tracked here. Distributed caching is imperative for external verifiers as they run as seperate processes and thus cannot share an in memory cache. Future testing will include external verifier scenarios.
Caveats
- The testing pipeline scrapes real time CPU/Memory metrics AFTER the workload has completed. Peak CPU/Memory usage is likely higher
- The original testing plan included a maximum of 20k pod workloads to test. This test has been excluded from the current test due to performance bottlenecks with the ClusterLoaderV2 tool. Investigation is required.
- As already noted above, the distributed caching at largest scale (10k pods) in the smallest region yielded anomalous results. Investigation tracked here
Azure Dev Ops Pipeline Implementation
Prerequisites (needs to be done once per subscription)
Set correct environment variables that are configurable
- Each configurable aspect of the pipeline will surface an environment variable that can be configured at runtime
Set subscription
Assign Identity and Roles
Upstream ADO runner identity assigned Owner access to target subscription
- Owner required for role assignment creation for access to centralized AKV and ACR that are persistent between runs
Create resource group
- Create premium ACRs for regions of different sizes
- Create AKV
Setup AKV & Push Artifacts to ACR
- Setup Notation Azure signing following directions here
- docker login to ACR
- Use
csscgenproject'sgenArtifacts.shscript to push artifacts to registry (see below)- currently only support notation but can be modified to generate arbitrary types of artifacts in future
Pipeline Execution
- Runner login using identity
- Update the az cli version and aks-preview cli version
- Generate load test resource group (this is where Workload identity and AKS cluster will live)
- Generate AKS Cluster, generate Ratify MI
- AKS
- options: (these are configured via env variables)
- node pool size
- workload identity enabled
- region
- kubernetes version
- max pods per node
- vm sku
- OIDC & workload identity enable the AKS cluster
- Attach ACR to AKS cluster
- options: (these are configured via env variables)
- AKV
- Grant get secret role to MI
- MI
- Create Ratify MI
- Create federated credential based on Ratify MI and service account
- Grant ACRPull role to MI
- AKS
- Install Gatekeeper
- options:
- replicas
- audit interval
- emit events
- enable external data
- audit cache
- GK version
- Apply GK config for excluding namespaces
- exclude: kube-*, gatekeeper-*, cluster-loader, monitoring
- options:
- Apply constraint template and constraint
- Generate resource templates:
- Create cluster-loader's config template by substituting env variables in the tepmlate file
- Clone
csscgenrepo and build the binary- use
csscgen genk8sto create deployment/job template based on registry host name, number of replicas, number of images, number of signatures
- use
- Install Ratify
- workload identity enabled
- AKV cert settings
- replicas?
- HA mode?
- Ratify version
- Use cluster loader (see below for more info)
- Scrape metrics and download logs
- port forward to localhost the prometheus endpoint for ratify
- parse scraped metrics to look for
- upload ratify + GK logs as artifacts
- Tear down cluster and delete resource group for test
csscgen tool
https://github.com/akashsinghal/csscgen
This repository combines the initial work done in the first round of perf testing for ratify. It creates a new CLI tool called csscgen that can be used to generate k8s resource templates for deployments/jobs based on the # of containers, # of replicas, # of referrers. It adds list of containers and populates each with the registry reference that is generated when the same tool is used to generate the artifacts to push to registry.
This tool is not related to Ratify and thus could be used in the future for other use cases.
The genArtifacts.sh script takes in the registry host name, # of images, & # of referrers and generates unique container image and referrers attached to it. These are then pushed to the registry. The naming of the images follow same convention used by the cssgen genk8s cli tool to generate the accompanying templates. TODO: in the future we can incorporate script into the csscgen tool.
Cluster Loader v2
https://github.com/kubernetes/perf-tests/tree/master/clusterloader2
This tool helps with generating and then loading arbitrary resources into a target cluster. It generates new namespaces and the specified copies of the target resource at different rates (QPS). It collects logs from the api server and watches for resource creation success/failure. Finally, a report is generated with resource consumption across the cluster during the cluster-loader process.